
(First published on March 1, 2021)
Part 1: The Basics
Artificial Intelligence has people fretting. High-profile disagreements among tech gurus make us wonder, anxiously, what the future will be like for ordinary people. If geniuses like Bill Gates, Elon Musk, and the late Stephen Hawking cannot agree on the usefulness and the relative benefits or dangers of AI, what hope is there for us to understand or even imagine how our lives will change? Will all of humanity live like kings and queens in a utopian world with robots providing for our every need? Or will those robots be in charge, banishing us to the wastelands? Is carbon-based life (that’s us) compatible with silicon-based life (that’s computers)? Are we heading for a power struggle? And, if that is our fate, who will win?
Let’s start by taking stock of the present: how is AI already influencing our lives, for better or worse?
But wait. Before we even do that, we first need to take a step back and talk about data[1]. Data might possibly be the most boring subject on Earth. “Could there be anything more boring?” Remember Chandler Bing in the iconic American sitcom, Friends? None of the Friends could remember what he did, because they lost interest in the middle of his job title and stopped listening. Give up? Chandler’s job was “Statistical Analysis and Data Reconfiguration”. This was the most banal, unfulfilling career the writers could come up with – in 1994.
Now, Data Scientist (literally doing statistical analysis and data reconfiguration) is the sexiest job of the 21st century. While the term “data scientist” appeared around 2010, the job search site Indeed.com reports that Data Science job postings increased 256% between 2013 and 2018, a pace faster than any other job category[2].
There is even a futuristic term for these modern cerebral sex symbols: “Quants” (short for Quantitative Analysts).
Data could be more valuable than anything else on the planet. Witness the recent exponential rise in value of companies that deal in data, such as Google and Facebook, compared to companies in more traditional industries such as ExxonMobil and General Electric[3] (figure 1). The COVID-19 pandemic amplified tech stocks, while recent geopolitical events such as the war in Ukraine and energy supply issues have complicated these trends, but the value of data cannot be understated. Data can entertain and inform us; data can save our lives; data can generate billions in profits. Data can swing elections – allegedly[4].
There are multiple facets to Data. It may be a small word, but it carries big assumptions and connotations. One of which is a default assumption of truth. When most people see the word “data” in a news article (“the data shows”, “data confirms”, “the data is in and it’s explosive!”) they don’t question the next sentence. This is potentially dangerous misplaced trust. Usually, when you see what is called data, it has already been “conditioned”, meaning it has been filtered, interpolated, extrapolated, and interpreted, perhaps even manipulated. No one shows you the raw data, because it is ugly, and it is certainly not obvious (even to a Quant) that it means anything.
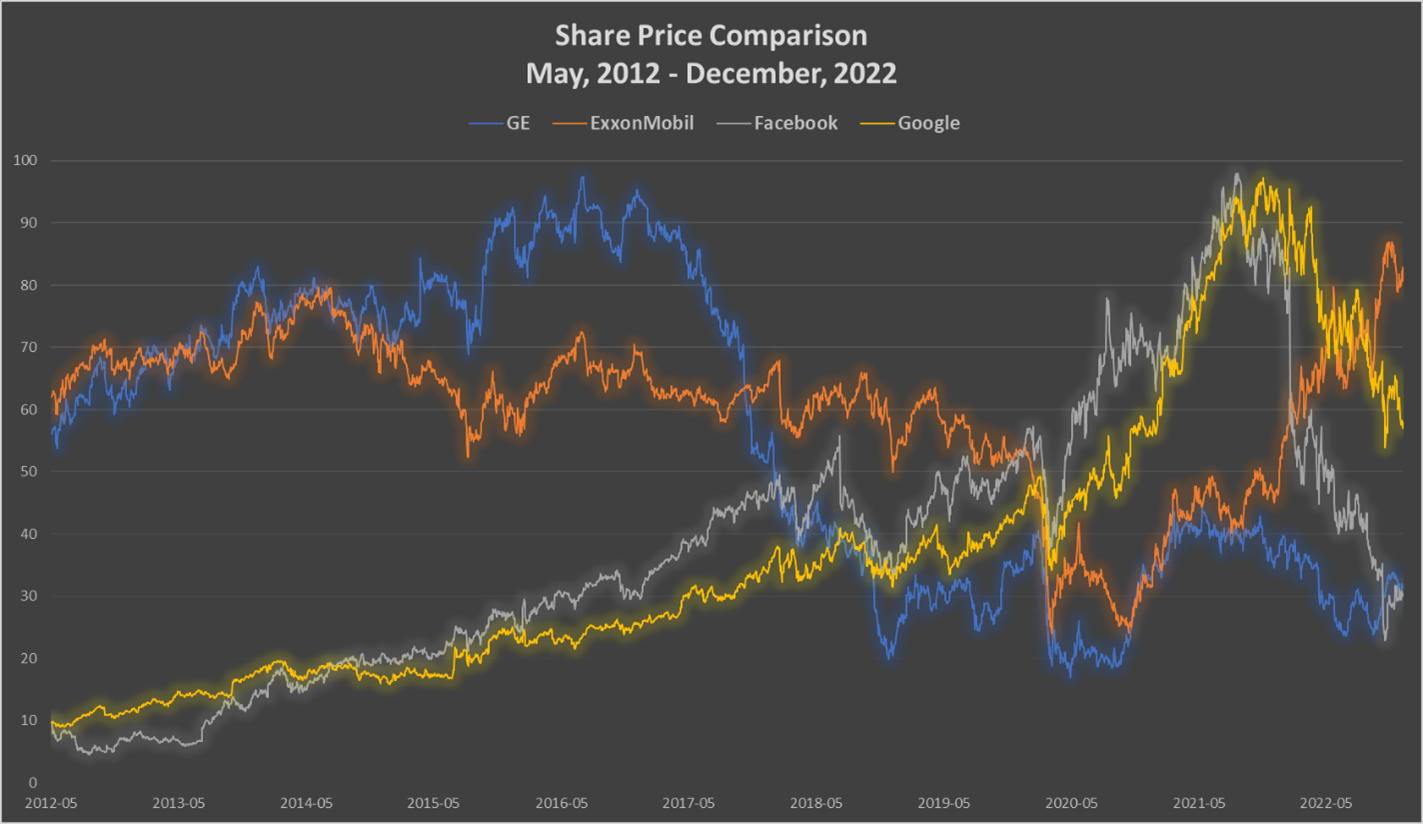
Figure 1: Normalized share price history for GE, XOM, FB (META) and GOOG, 2012 to 2022.
However, although truth is in the raw data, it (the data) may not be complete, impartial, or, more worryingly, correct. The act of collecting data is an art and a science in its own right. Consider the humble telephone survey: a pleasant person reading from a script provided in a call center, asks a series of questions which are designed to gather appropriate data for a predetermined objective. In many cases, the questions are ambiguous, leading, or misleading. The people reached by the phone call need to have a phone, answer it, and have the time and be willing to answer the questions, all of which impose sampling biases before the first data point is collected. Statisticians have long dealt with these shortcomings and have devised methods to identify biases and gaps in the data and extrapolate or filter to mitigate the effects. But some damage has been done – we have already introduced uncertainty.
We can even influence the data through the act of measuring. On the atomic scale, this is referred to as the Heisenberg Uncertainty Principle[5]. Since atomic particles are so small, the light waves/particles utilized for the observation affect the behaviour of the particles themselves, meaning that we can never accurately observe the unobserved particle action. Similarly, when studying gorillas in the wild, some researchers have facilitated observations by attracting gorillas to study sites with food, thereby introducing competition for the “free” bananas, changing normal gorilla behaviour in the process[6].
Quants are data tamers, assessing uncertainty, challenging methods, recognizing trends within trends, wrangling unruly outliers, muffling the noise, and revealing valuable insights. Kind of like gold prospectors of olden times, sifting through mountains of gravel to find nuggets they can take to the bank. The difference is, data is much richer, subtler, more mysterious, secretive, multi-dimensional, and, more often than not, misleading, than a pan full of grit with an obvious shiny flake in it.
Now, to get back to the AI story:
AI represents the computer methods and algorithms that Quants use to do their jobs (sometimes Quants are responsible for programming the algorithms in the first place). AI is all about empowering computers to rapidly consume petabytes[7] of data and reveal hidden meaning; the type of meaning that can be used to categorize groups or trends, predict causes and effects, or provide insights into future behaviour. The process of discovering meaning in groups of numbers or records encompasses three main steps: collect, process, and interpret. These steps sound straightforward, but, as we examine each stage in a little more detail, there are unexpected and potentially fatal – in the integrity sense – pitfalls lurking.
As we have already seen in our telephone survey, the initial collection can be deficient, so data needs to be “cleaned”, which usually means a person or algorithm looks at the data and ensures gaps are filled with reasonable interpolations, biases are recognized and suppressed, and that it fits some common-sense criteria, such as an age range between 18 and 99. Anything outside of that range might be considered bad data and deleted or flagged.
Next, computers process the data using various appropriately chosen mathematical algorithms with names like “generative adversarial networks (GANs)”, relying heavily on “training” data. Training data is as critical to AI as reliable data collection and involves many, many examples of interpreted data identified and labelled (generally by human experts) to establish a database for the computer to reference. If the training data is not abundant enough, or is mis-labelled, the algorithm risks producing completely meaningless results. The danger is that the results appear meaningful and are bestowed with an undeserved confidence.
Finally, when the processing is complete, the next step is to interpret, or assign real-world significance to the result. This step is the reason for the whole process. If this is not done correctly or meaningfully, there was really no point to the first two steps. Once again, human subject-matter experts are necessary to fit the final interpretation options into realistic parameters.
Notice anything in common among these three steps? They all require, to some degree, judgement by a human or group of humans, or algorithms designed by humans, to assess quality and assign criteria. These human brains can therefore impose cognitive, cultural, or moral biases and preferences. This may seem like it defeats the purpose of the computer analysis. However, human involvement is an essential component that constrains the computer results to the realm of the realistic. AI experts refer to the process as “brittle” if the AI results are very different given slight changes to the human input or model constraints.
Keep in mind that although human judgement is important to the effective AI process, human brains are very good at some things and very bad at other things.
Our human brains collect, process, and interpret considerable amounts of data every second. Consider facial recognition: while computers are gradually acquiring basic facial recognition ability, humans do not question their own capacity to recognize faces or categorize unrecognizable ones. Every person you see as you walk down the street, provides data to your brain which you are unconsciously comparing to your database and making instantaneous judgments (friend, lover, foe, good looking, trustworthy, interesting, smart, etc.). These new inputs are also adding to and strengthening your own personal database of experience, judgement, and categorization.
Computers may have trouble recognizing your face if you get new glasses or shave your mustache, but even if you have not seen your grandmother in many years, her hair is different, she is wearing different lipstick, new glasses, a hat you have never seen, and she has new teeth, you still recognize her instantly. This comes naturally to us but is currently a considerable challenge for a computer. I have noticed that even on my state-of-the-art new phone that uses facial recognition to unlock it, if I am laughing or yawning when I look at the phone, it is not sure it is me and asks me to type my password. We wouldn’t have that problem with a face we knew.
However, human brains are easily distracted and fooled. They get tired and hungry. Our brains are influenced by emotion, cultural perspective, and unconscious bias at least as much, and perhaps more than, by rational analysis. Enter the eternally energetic, perpetually eager, cold, calculating computer. It is a perfect match. Carbon, meet Silicon. Just like any relationship, this partnership will have its rough spots, but it can be a beautiful collaboration if we recognize and appreciate our strengths and differences.
[1] The word “data” is, strictly speaking, plural; “datum” is the singular form. We should therefore say that “data are boring”. That can sound formal and a little academic; anyway, it is largely accepted to use the word in the singular form as perhaps an abbreviation for “dataset”. In this article, I have chosen the singular usage.
[2] What Indeed’s Job Market Data can tell us about Demographics and Trends in Data Science
[3] Data source: https://finance.yahoo.com/quote
[4] https://www.thegreathack.com/
[6] Ethical Issues in African Great Ape Field Studies
[7] Digital information is measured in bytes. Adding Greek prefixes to “byte” signifies multiples of the individual byte. For example, a “kilobyte” is 1000 bytes, each of “mega”, “giga”, “tera”, and “peta”, prefixes add, in turn, another multiple of 1000. The petabyte is, therefore, 1000 terabytes, or 1,000,000,000,000,000 bytes. Computer storage and processing is getting so large that soon, we will be referring to “exabytes” of data, which are 1000 petabytes.
(Laurie Weston – BIG Media Ltd., 2021)

